 By Chrissy Kidd November 03, 2022
By Chrissy Kidd November 03, 2022
There is more data available to us than ever. Storing this data is important — but deciding on the right type of data storage solution is not so clear.
This article explores two primary types of big data storage: data lakes and data warehouses. We’ll examine the benefits of each, then discuss the key differences between a data lake and a data warehouse, so you can decide on the best approach for your business.
TLDR: data lake vs data warehouse
The general rule of thumb is in their names:
- Data warehouses are organized and more immediately useful to business needs, though with certain limitations.
- Data lakes are immense and could contain…all sorts of data, raw, unstructure — whatever!
- And we'll touch briefly on other storage, like data lakehouses, databases and data marts.
Let’s get started!

Data lake, data warehouse… database? Data lakehouse?
Before we dive into the topic of a data lakes and warehouses, it’s important to note that neither is classed as a database. A database is a collection of structured data and is best utilized for storing and analyzing relatively small data sets. There can still be a lot of data (and information) stored in a database, but nothing on the scale of big data storage solutions.
Enter data lakes and data warehouses. Both solutions store a much larger amount of data than a database and both also support overall data mangement — but that’s about where the similarities end. There are fundamental differences between lakes and warehouses, including:
- Their overall purpose
- The types of data they collect
- How they’re structured
- Who can use them
Let’s look at what each type involves...
What is a data lake?
A data lake is a large repository that stores huge amounts of raw data in its original format until you need to use it. There are no fixed limitations on data lake storage. That means that considerations — like format, file type and specific purpose — do not apply. Data lakes can store any type of data from multiple sources, whether that data is structured, semi-structured or unstructured.
As a result, data lakes are highly scalable, which makes them ideal for larger organizations that collect a vast amount of data. Data lake solutions are appealing as they act as a place to temporarily store data without the need to transform the data first. When specific data is needed, it can then be queried and analyzed in virtually any way you choose.
What is a data warehouse?
In contrast to the limitless realm of data lakes, data warehouses store large amounts of structured data that is filtered and organized for a specific purpose.
As with data lakes, data in a data warehouse is also collected from a variety of sources, but this typically takes the form of processed data from internal and external systems in an organization. This data consists of specific insights such as product, customer, or employee information.
With their rigid structure, the queries and analysis that can be performed using data warehouse information is fixed. Businesses have been traditionally drawn to data warehouses due to the ease of sharing department-specific data and content to guide decisions made by management teams. A well-known data warehouse is Snowflake, but there are several others including from the Big 3 cloud service providers.
What about data lakehouses & data marts?
- Data lakehouses are a newer technology, which actually combine certain functions of data warehouses and data lakes. Check out our full data lakehouse explainer.
- Data marts are, in a way, a subset of data warehouses. Data marts serve the needs of a specific business unit, like the marketing team or the product team.
With all this data being stored, you might want to think about the observability of that data and the systems it supports. Observability answers the question: “What is happening inside this app or across a system?”

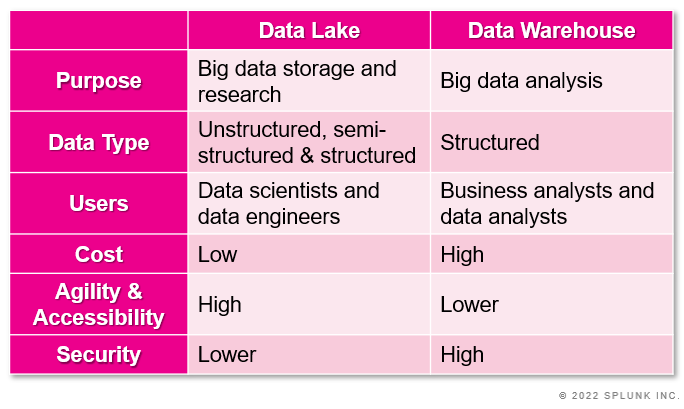
Data lake vs. data warehouse: the 6 main differences
You’re probably seeing how the uses and practicalities of data warehouses versus data lakes can differ considerably. To help expand our understanding of the core differences between a data lake and a data warehouse, let’s break down each solution into six comparative points:
- Purpose
- Data structure & schema
- Users
- Cost
- Accessibility and agility
- Security
Purpose/use case
Data within a warehouse is refined in order to be used for a specific purpose — perhaps log and event management, sales reporting or security analysis. In contrast, raw data in a data lake does not yet have a particular purpose but is retained in case it is deemed relevant for future use. (This approach, however, does come with longer-term hazards about the cost and sustainability of storage, when we already know that only 10% of collected data is actually used and applied.)
There can be an overlap in how both solutions work together in a company’s data pipeline. Most enterprise data will end up in data lake storage, but if there is a specific business request, relevant data can be extracted, filtered, and refined. This new, processed data can then be exported into a data warehouse.
Data structure & schema
Data warehouses only store structured, refined data, whereas data lakes can store any form of raw data: unstructured, structured, and semi-structured.
More specifically: In data lakes, schema refers to the organization and structure of the data stored in the lake. That means a data lake does not impose a strict schema on the data it contains. Instead, data is stored in its native format, and the schema is applied when the data is queried or analyzed. This is known as schema-on-read, which allows for more flexibility and agility in data processing, as new data can be added to the lake without requiring a pre-defined schema.
In contrast, a data warehouse typically uses a pre-defined schema to organize and structure the data, known as schema-on-write. The schema is designed to optimize query performance and ensure data consistency.
Data is typically transformed and cleaned before being loaded into the warehouse to conform to the schema. This approach provides greater control over the data and can lead to better query performance, but it can also be more rigid and less adaptable to changing data requirements. Basically, when it comes to data structure, we can sum it up like this:
- A warehouse is a home for processed data.
- A data lake can house any type of unfiltered data from multiple sources.
(Read about ETL, data normalization and, yes, even data denormalization.)
Users
Another differentiating factor of data lakes vs. warehouses is the user. Who is using which storage?
- A data warehouse can usually be set up and interpreted by a data analyst or business analyst, providing that they have an awareness and knowledge of the functions/outcomes of that specific processed data set.
- Data lake solutions are more complex due to the vast quantities of unstructured data present, which requires the specialist knowledge of a data scientist or data engineer. These professionals are able to interpret and organize unprocessed data before it can be analyzed, which requires employing and/or outsourcing experts.
Cost
Data lakes are designed to be more cost-effective than data warehouses. By storing large amounts of data of any structure, they are more flexible and scalable due to the removed need for data to adhere to a fixed schema. Practically speaking, depositing huge quantities of data in one place takes away the need for filtration, which can amount to higher storage costs associated with data warehousing.
The trade-off of higher costs is the fact that structured data in a data warehouse can be analyzed more quickly and easily than data in a lake.
Accessibility/agility
As you may recognize, another difference between data warehouses and data lakes is their structural disparity:
- Data lakes are agile by nature, allowing data to be added and stored more easily. It also means that they’re flexible enough for data scientists and developers to configure data models and applications, and enable tools for big data analytics.
- Data warehouses have a specific structure and are more difficult to alter. They typically have a ‘read only’ format which analysts can scan to garner insights from historical, clean data.
Security
Data lakes store petabytes of information — that’s 1,000 terabytes per unit! Their sheer size and their lack of selectivity on the data stored means that they’re inherently less secure than a more compact, structured data warehouse.
In addition to this, data warehouse technology is a lot more established than the relatively new big data technologies. That is: data warehouse security is mature in comparison. Big data security measures are rapidly evolving however, so it’s likely that data lakes will eventually become more secure.
(Understand data security through the lens of cyber hygiene.)
Choosing a data lake or data warehouse
Data lakes and data warehouses are fundamentally very different storage solutions, each with their own pros and cons:
- Warehouses are more secure and easier to use, but more costly and less agile.
- Data lakes are flexible and less expensive, but they require expert interpretation and lack the same level of security.
When do you use which? Using the two in tandem is often a sensible strategy for businesses. If there’s an existing data warehouse in operation, then implementing a data lake to store new data sources could be the most valuable option. That way, a data lake can act as both an information bank and an archive repository of the data moved out of a warehouse.
Some enterprises choose a data lake over a warehouse model because of its increased capacity and agility, but experts caution this approach. As the newer of the two solutions, there is more scope for unprecedented errors than with a data warehouse, amidst other factors such as:
- Data latency
- Data overindulgence
- Regulatory issues
Data warehouse and data lake solutions
Every organization requires a bespoke data warehouse and/or data lake solution, and there’s no “one size fits all” approach. Let’s briefly look at how these storage solutions work with different types of technologies, tools and platforms:
- Data warehouses are grouped with relational database technologies because of their ability to query structured data at a high speed. The evolution of relational database models (for both software and hardware) will enable data warehouses to be faster, more reliable, and ultimately more scalable.
- Data lakes benefit more from big data technologies, particularly those that can enhance data lake analytics. Programs like Hadoop can process large quantities of data in any format, promoting the adaptability and scalability of a data lake. In addition to this, Hadoop can apply structured views to unprocessed data in a warehouse.
- Cloud solutions also shape data storage methods. Cloud management services for data lakes are being offered by organizations such as Amazon S3, Google and Azure Data Lake. Data warehouse companies are also improving the customer cloud experience which will facilitate a better way to buy and expand a warehouse at a much lower cost.
- The impact of machine learning in data warehousing will also improve data warehouse solutions. Because machine learning and AI rely on near-real-time data, which warehouses can provide, as the use cases for ML grows, we can expect improvements in tandem technologies. When creating ML models, the majority of time will be spent preparing data- the rest is execution. Data warehouses can eliminate the preparation step, which can save even more time and lead to better, more refined analytical results.
Technologies are constantly evolving and will continue to shape the role of data lakes and data warehouses, but deciding on a solution depends on your current capabilities, budget, resources, and long-term goals.
Use data wisely (we’re not all data experts)
At the end of the day, companies can only gain value from their data if it can be used to make smarter decisions. Fundamentally, any data storage strategy should consider all stages of the supply chain, taking into account how data can be found, stored, organized, aggregated and transformed.
We should also consider our own interpretation of data. it is easy to believe numbers just because they are displayed in slides or a presentation, but asking a few questions will help you to understand the information — and whether it is worthwhile of our trust.
There are advantages and disadvantages to both data warehouses and data lakes, but as we’ve explored, the best data storage solution for your organization balances efficiency with resources and requirements. Staying abreast of developments with regards to both methods, and carefully considering which model would work for your specific enterprise will enable your business to grow and thrive.
What is Splunk?
This article was written in collaboration with Ailis Rhodes and does not necessarily represent Splunk's position, strategies or opinion.